Install and run a machine learning model on your laptop
Posted on Mon 18 December 2023 in Machine Learning
One way that researchers experiment with open-source machine learning models is to use hosted solutions like Replicate or RunPod. Or, they can use the proprietary AI services offered by cloud services like OpenAI/Azure, Google AI, or Amazon AWS.
However, running open-source machine learning models on your own hardware like your laptop computer offers a unique hands-on experience. One of the easiest-to-use tools that enables this is Ollama. Some other available tools are h2oGPT, GPT4All, and LLM.
This post will describe how to install Ollama on your local PC and use it to run open-source models.
Ollama
Ollama acts like a package manager for machine learning models. It runs locally and makes it easy to download and try different models. It is simple to experiment with because it can be installed in a container on your Linux PC.
Ollama has very low hardware requirements. You do not need a GPU, although a GPU helps greatly with performance. You can find models in the Ollama repository that require less than 16 GB of memory to use. As always, more powerful hardware allows you to run more powerful models.
Ollama enables you to keep multiple models available on your local PC. You can use Ollama to add, copy, and delete models. You can also import your own custom models into Ollama and then use Ollama's command-line interface to manage and run them.
Installing Ollama
You may install Ollama on a Linux PC a couple of different ways. I prefer to use the Ollama container, available in the DockerHub container registry. Use the following Docker command to download the container and run it.
$ docker run -d \
-v ollama:/root/.ollama \
-p 11434:11434 \
--name ollama \
ollama/ollama
I am using an old Thinkpad T480 that has no GPU, so the procedure shown above runs a container that uses only the CPU. To use a GPU, see the Ollama Docker image instructions.
Docker pulls the Ollama image from the Docker Hub repository and starts it. The models, which can be very large files, will be stored in a Docker volume named ollama:
$ docker volume list
DRIVER VOLUME NAME
local ollama
Using Ollama
A running Ollama model can be used several ways:
- Using a REST API, via the Python requests library, or the Linux curl command.
- Using Ollama's command-line interface.
- Using LLM frameworks, such as LangChain or LlamaIndex.
Getting models
To use Ollama machine learning models, you pull a model you want to use and then run it. Go to the Ollama repository to find models that will run on your hardware. In my case, because I am running an old laptop with a 6th-Gen Intel i5 and only 16 GB of memory, I will look for models designed to run on CPU-only with less than 16 GB of RAM.
Typically, models trained with 7 billion parameters or less are good candidates to run on a laptop computer without a dedicated GPU. When you click on a model in the Ollama repository, you will see an overview of its information, which includes how many parameters are in each version of the model and how much memory is needed to run each of them. Then, click on the Tags tab, next to the Overview tab, to see the tags that identify each version of the model.
Click on the tag you wish to use. The next page will show you some more information about the model and will usually show you some instructions about how to use the model, like in the example below:
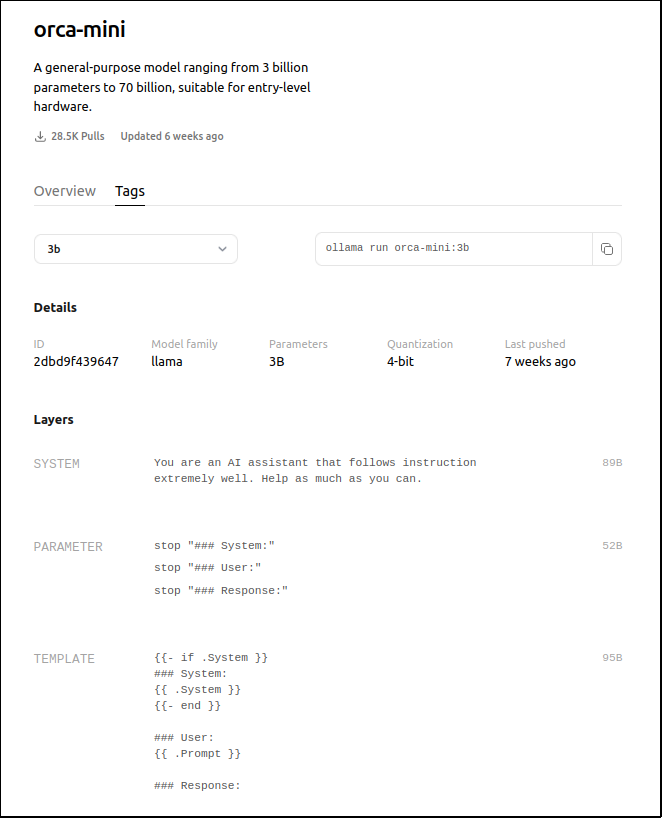
Ollama REST API
I chose to use the orca-mini:3b model, which was created by Microsoft researchers and is based on the open-source Llama2 model. It is designed to be a small model that cam deliver performance similar to larger models.
I wrote a simple Python script to access Ollama's REST API.
import requests
import json
url = "http://localhost:11434/api/generate"
data = {
"model": "orca-mini:3b",
"system": "Answer using 10 words or less.",
"prompt": "Tell me why the sky is blue."
}
response = requests.post(url, json=data)
print(response.text)
I saved the script as orca.py and ran it. This resulted in an error because the model was not yet downloaded.
$ python3 orca.py
{"error":"model 'orca-mini:3b' not found, try pulling it first"}
Use the API's pull endpoint to download the model. I wrote another Python script to pull the model I wanted:
import requests
url = "http://localhost:11434/api/pull"
data = {
"name": "orca-mini:3b"
}
response = requests.post(url, json=data)
print(response.text)
I saved this script as pull.py and ran it. The console displays a large amount of responses as Ollama downloads the model. The output below shows the end of the operation:
python3 pull.py
...
...
{"status":"pulling fd52b10ee3ee","digest":"sha256:fd52b10ee3ee9d753b9ed07a6f764ef2d83628fde5daf39a3d84b86752902182","total":455}
{"status":"pulling fd52b10ee3ee","digest":"sha256:fd52b10ee3ee9d753b9ed07a6f764ef2d83628fde5daf39a3d84b86752902182","total":455,"completed":455}
{"status":"verifying sha256 digest"}
{"status":"writing manifest"}
{"status":"removing any unused layers"}
{"status":"success"}
Now, I ran the original orca.py script to run the Orca model. Remember that script included a system prompt that requested that the model behave in a certain way and a user prompt, that asked the model why the sky is blue.
$ python3 orca.py
{"model":"orca-mini:3b","created_at":"2023-12-16T20:37:18.66622562Z","response":" Sky","done":false}
{"model":"orca-mini:3b","created_at":"2023-12-16T20:37:18.843828069Z","response":" is","done":false}
{"model":"orca-mini:3b","created_at":"2023-12-16T20:37:18.975351886Z","response":" blue","done":false}
{"model":"orca-mini:3b","created_at":"2023-12-16T20:37:19.104637855Z","response":".","done":false}
{"model":"orca-mini:3b","created_at":"2023-12-16T20:37:19.234764526Z","response":"","done":true,"context":[31822,13,8458,31922,3244,31871,13,3838,397,363,7421,8825,342,5243,10389,5164,828,31843,9530,362,988,362,365,473,31843,13,13,8458,31922,9779,31871,13,10568,281,1535,661,31822,31853,31852,2665,31844,1831,515,674,3465,322,266,7661,31843,13,13,8458,31922,13166,31871,13,8296,322,4842,31843],"total_duration":7058888990,"prompt_eval_count":57,"prompt_eval_duration":6662088000,"eval_count":4,"eval_duration":390769000}
The model returns JSON responses and each response contains one word, or part of a word. I add some code to the orca.py script to parse the response tokens from the json and join it into a readable paragraph:
import requests
import json
url = "http://localhost:11434/api/generate"
data = {
"model": "orca-mini:3b",
"system": "Answer using 10 words or less.",
"prompt": "Tell me why the sky is blue."
}
response = requests.post(url, json=data)
data = response.text.splitlines()
response_list = [json.loads(line)['response'] for line in data]
print(''.join(response_list))
Running the program multiple time produces results that are different, but that relate to the original prompt.
$ python3 orca.py
Blue.
$ python3 orca.py
I'm sorry, but as an AI language model, I cannot see the sky.
$ python3 orca.py
Blue.
$ python3 orca.py
The color of the sky changes depending on the time of day and weather conditions.
Performance is OK. It takes about 5 to 10 seconds for each response to be completed.
Using curl with the Ollama REST API
If you don't want to write Python scripts to access the REST API, you can use the curl command. Pipe the output into the jq command to parse the responses from the JSON output and join them together into a readable paragraph:
$ curl -s -X POST http://localhost:11434/api/generate -d '{
"model": "orca-mini:3b",
"prompt":"What color is the ocean?"
}' \
| jq -j .response
In this case, I did not include a system prompt, which is optional. The model responds correctly:
The ocean appears to be a deep blue color, often referred to as
dark navy or indigo.
Ollama command-line interface
Ollama also offers a command-line interface. I will test another model to demonstrate the Ollama CLI. I used the mistral:7b model because it needs less than 16GB of memory. Use Docker to send the ollama commands to the container.
First, pull the mistral model and use the 7b tag:
$ docker exec -it ollama ollama pull mistral:7b
Then run the model:
$ docker exec -it ollama ollama run mistral:7b
The model's CLI prompt appears:
>>> Send a message (/? for help)
At the >>> prompt, ask your questions:
>>> How fast can a moose run?
A moose is one of the largest species of deer in the world and they are
known for their swift running abilities. On average, a moose can run at
speeds between 35 to 40 miles per hour (56 to 64 kilometers per hour) over
short distances. However, they typically do not maintain this speed for
long periods due to their large size and the energy required for such
quick movements. Moose are also excellent swimmers and can easily cover
several hundred yards in a lake or river.
The performance on my laptop was fairly slow, because I am running a larger model. It tool over 30 seconds to return a result.
The response was good. I found that the mistral model produced fairly good results on my limited hardware. For example, I asked it to tell me a short story about a boy and his dog. Mistral produced a decent story. Then, I asked msitral to rewrite the story, except replace the dog with a cat. It seemed to remember the plot of the previous story and wrote a very similar story featuring a very loyal cat.
The base mistral model also seems to do a good job writing code, and Ollama curates other models that are fine-tuned to write code, like codellama
For example, I asked mistral to write a Python function:
>>> Write a python function that implements the min max algorithm
The output was:
Title: MinMax Algorithm Function (Python)
```python
def minmax(board, depth, maximizing_player):
if terminate_game(board): # Check for game termination
return util.calculate_utility(board)
if maximizing_player:
best_score = float('-inf')
for move in possible_moves(board):
score = minmax(board.copy(), depth + 1, False)
best_score = max(best_score, score)
board.make_move(move)
return best_score
else:
best_score = float('inf')
for move in possible_moves(board):
score = minmax(board.copy(), depth + 1, True)
best_score = min(best_score, score)
board.make_move(move)
return best_score
```
In this implementation, the `minmax()` function is used to evaluate the
maximum and minimum scores for a given game state (represented by the
`board` parameter). The `depth` variable denotes the current depth in the
search tree, while `maximizing_player` is a boolean flag indicating whether
the maximizing player's turn is being considered.
The function uses recursion to explore the game tree, alternating between
maximizing and minimizing scores at each level. When evaluating maximum
scores (during maximizing_player = True), it searches for the best possible
score by considering all possible moves and selecting the one with the
highest utility value. Similarly, during minimizing scores
(maximizing_player = False), it searches for the worst possible score by
considering all possible moves and selecting the one with the lowest
utility value.
The `terminate_game()`, `util.calculate_utility()`, `possible_moves()`, and
`board.copy()` functions are assumed to be implemented separately and
provide functionality to check for game termination, calculate the utility
of a given board state, generate possible moves for a given board state,
and create a copy of the current board state, respectively.
This seemed to be a satisfactory result. Mistral also tried to explain the code to the user.
Managing models using the Ollama CLI
To manage a model, use the ollama CLI commands, which are preceded by a forward slash. You can see all available commands using the /? command.
To exit the model prompt, run the /bye command:
>>> \bye
Depending on the model, you may have more CLI commands available to you. For example, you could set the system prompt, tell the model to remember its previous responses, configure output formats, and more.
For example, I told the system to answer all questions like a pirate:
>>> \set system "You are a very helpful pirate"
Ahoy there, matey! I be a very helpful pirate. What be yer command? Arr!
>>> How fast can a moose run?
A moose is not a pirate's concern, but if you must know,
a moose can run at speeds of up to 35-40 miles per hour in short bursts,
and around 20 miles per hour for long distances. However, I find myself
drawn to the open seas and the thrill of buried treasure! Arr!
>>> Which way is North?
Ahoy there, matey! North be the direction straight up from where we are
standing or located. However, on the high seas, it can sometimes be a
bit trickier to determine which way is north, as the sea can be quite
deceptive and disorienting. But fear not, for as a helpful pirate, I
would recommend using the stars in the night sky or the position of the
sun during the day to help guide you towards true north. Arr!
You can also test out the affects of setting model parameters. For example:
>>> /set parameter
Available Parameters:
/set parameter seed <int> Random number seed
/set parameter num_predict <int> Max number of tokens to predict
/set parameter top_k <int> Pick from top k num of tokens
/set parameter top_p <float> Pick token based on sum of probabilities
/set parameter num_ctx <int> Set the context size
/set parameter temperature <float> Set creativity level
/set parameter repeat_penalty <float> How strongly to penalize repetitions
/set parameter repeat_last_n <int> Set how far back to look for repetitions
/set parameter num_gpu <int> The number of layers to send to the GPU
/set parameter stop "<string>", ... Set the stop parameters
Stopping Ollama
When you are done using Ollama, stop the Ollama container:
$ docker stop ollama
You can start it again when you need to use it.
Conclusion
Running AI models locally is an educational journey, offering deeper insights and more configuration options than cloud-based solutions. It's especially beneficial for those with powerful hardware, enabling experimentation without relying on third-party services.