Use Python to read data from a database
Posted on Fri 02 June 2023 in Databases
In today's data-driven world, businesses realize that the ability to extract insights from vast amounts of information is crucial to success. Python has emerged as a popular language for data analysis and manipulation. Python's extensive library ecosystem offers powerful tools that help streamline the process of working with structured data stored in SQL databases.
In this blog post, we will explore how to leverage Python and the pyodbc library to read data from a SQL database, empowering you to unlock valuable insights and drive data-informed decision-making.
Read-only
When working as a data analyst or data scientist, you often read data from a database but you usually do not need to write data to a database. In fact, if you work with data provided by other teams, they almost always will restrict your database access privileges to read-only. The other team's database administrator may give you access to a database view that is read-only and contains only the table columns you requested when you discussed your data needs.
The SQL and Python code shown in this post covers the simple case of reading data. Writing or changing data in a database is a more complex topic and I do not cover it in this post.
Set up your Python environment
Before you start working through this tutorial, you need to set up your Python virtual environment and install the necessary packages on your computer. The details of these steps are covered in my previous posts about using dotenv files, creating a sample database and reading database schema. I summarize the steps, below.
These examples were created on a laptop computer running Ubuntu 22.04. I assume Python is already installed on your system. If not, follow the instructions at www.python.org.
Create a new Python virtual environment. In my case, I created the virtual environment in the new folder I created for this project.
$ cd data-science-folder
$ python3 -m venv .venv
$ source ./.venv/bin/activate
(.venv) $
I suggest you install Jupyterlab so you can follow the steps in this tutorial more easily. If you do not use Jupyterlab, then you may use any text editor or the Python REPL.
(.venv) $ pip install jupyterlab
This tutorial uses the Microsoft AdventureWorks LT sample database running on Microsoft Azure. Follow my previous post about creating a sample database on MZ Azure's free service tier to create a similar sample database you can use to follow along with the steps in this post.
Then, install the Microsoft ODBC Driver for SQL Server on your PC:
(.venv) $ sudo su
(.venv) $ curl https://packages.microsoft.com/keys/microsoft.asc | apt-key add -
(.venv) $ curl https://packages.microsoft.com/config/ubuntu/$(lsb_release -rs)/prod.list > /etc/apt/sources.list.d/mssql-release.list
(.venv) $ exit
(.venv) $ sudo apt-get update
(.venv) $ sudo ACCEPT_EULA=Y apt-get install -y msodbcsql18
Install the pyodbc library in your Python virtual environment.
(.venv) $ pip install pyodbc
(.venv) $ sudo apt install unixodbc
Install the python-dotenv package:
(.venv) $ pip install python-dotenv
Install the tabulate package so you may more easily format your output during this tutorial.
(.venv) $ pip install tabulate
Connect to the database
Create a dotenv file and add the database connection string to it. If you are using an example database on Azure, the string will look similar to the one below.
(.venv) $ echo 'CONN_STRING="Driver={ODBC Driver 18 for SQL Server};'\
'Server=tcp:sqlservercentralpublic.database.windows.net,1433;'\
'Database=AdventureWorks;Uid=sqlfamily;Pwd=sqlf@m1ly;Encrypt=yes;'\
'TrustServerCertificate=no;"' > .env
Use your own values for server name, database name, user name, and password.
IMPORTANT: If you are using a source control service like GitHub, ensure that you except the .env file from being tracked so you do not place database credentials in a public repository.
Open a new Jupyterlab notebook (or use the Python REPL) and run the following Python code to connect to the database.
import os
import pyodbc
from dotenv import load_dotenv
from tabulate import tabulate
load_dotenv('.env', override=True)
connection_string = os.getenv('CONN_STRING')
conn = pyodbc.connect(connection_string)
print(conn)
You should see the connection information in the output. It should look like the following:
<pyodbc.Connection object at 0x0000014F5D0C1CA0>
In the rest of this tutorial, you will use the database connection instance, conn, to create cursor instances that will read and return database results to your program.
Database schema
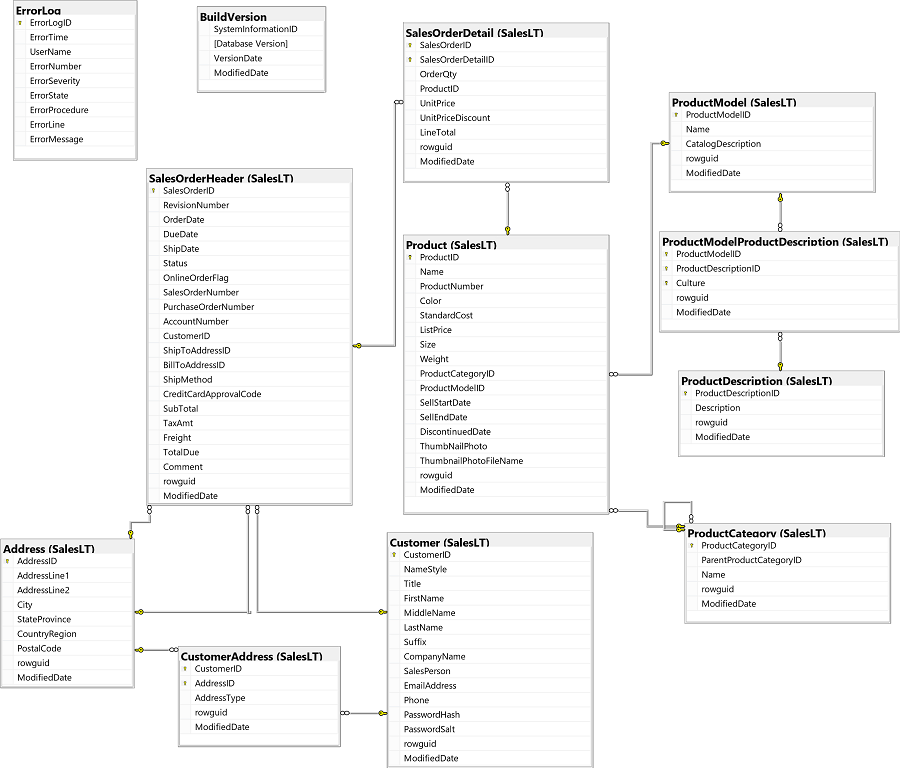
If you read my previous post, you should already know the tables in the AdventureWorks LT database and the columns in each table, and the data relationships defined by the primary and foreign key constraints. You can usually get database schema information from the database documentation but here is no official documentation for the AdventureWorks LT database. The database diagram is shown below 1:
Using cursor methods
In this post, I show you how to use the cursor instance's execute() method to load SQL statements into the cursor so that they can be executed by the fetchall(), fetchmany(), fetchone(), or fetchval() method.
Other cursor instance methods, such as the methods used to discover the schema of a database, are not covered in this post. Those methods were already covered in the appendix of my previous blog post about exploring SQL database schemas.
Also, since we are focusing on read-only actions, the methods related to writing data are not covered in this post.
Create a cursor instance
Create a new database cursor using the connection instance, named conn. Add the following code in a new Jupyter Notebook cell or just add it to your Python program and run it.
cursor = conn.cursor()
Now you have a database cursor instance named cursor that comes with attributes and methods you can use to query data from the database.
Managing the cursor instance
When you are done using the cursor, you may close it using the close() method by running the statement, cursor.close().
Alternatively, you can create the cursor in a context manager using the Python with statement. Then the cursor will automatically get closed when the with block ends. You will see examples using the context manager later in this post.
SQL statements
SQL (Structured Query Language) serves as a universal method for interacting with relational databases. It empowers you to query and retrieve data by crafting specific commands that match your data needs.
If all you need to do is get data from a database so you can use other tools like pandas or spark to transform and analyze it, then you need to learn only about the most basic SQL topics, like the SQL SELECT statement.
As your data extraction and transformation needs become more advanced, you will learn more about SQL so you can create powerful operations using SQL statements. I cover some useful, but simple, T-SQL examples later, in the Examples section.
To execute SQL statements on the SQL server, the pyodbc driver requires that you create a string that contains an SQL statement and pass it as a parameter of the cursor instance's execute() method. The example below assigns a string to a variable named statement. The string contains an SQL statement that reads all the data contained in one of the views in the AdventureWorks LT database.
statement = """
SELECT *
FROM SalesLT.vGetAllCategories
"""
The vGetAllCategories view was pre-defined in the AdventureWorks LT sample database. It will display the list of product categories in the database with their parent categories. If you want to use the command that will display SQL statement that created the view, read my previous post about reading the database schema.
Executing SQL statements
Use the cursor instance's execute() method to point the cursor to the start of the results returned by running the SQL statement on the SQL server.
cursor.execute(statement)
At this point the results of the SQL query are cached on the server and have not been downloaded into memory on your computer. The cursor instance does not actually contain data. The data is pulled from the database when you use one of the cursor's fetch methods so you can control how much data you retrieve across the network.
Cursor attributes
After executing an SQL SELECT statement, the cursor instance will contain some information about the results, in addition to the actual data results. One attribute that you may find useful is the description attribute.
The description attribute returns a tuple containing nested tuples that describe each column that will be returned by one of the cursor's fetch methods. For example:
from pprint import pprint
with conn.cursor() as cursor:
cursor.execute(statement)
pprint(cursor.description)
The Python statement above returns the following object:
(('ParentProductCategoryName', <class 'str'>, None, 50, 50, 0, False),
('ProductCategoryName', <class 'str'>, None, 50, 50, 0, True),
('ProductCategoryID', <class 'int'>, None, 10, 10, 0, True))
The column name is the first item in each nested tuple. This will be useful for building a list of column headers that we can use later as a parameter to the tabulate function. You can run a list comprehension statement to build a headers list:
with conn.cursor() as cursor:
cursor.execute(statement)
headers = [h[0] for h in cursor.description]
print(headers)
The table's column headers are now available in a list:
['ParentProductCategoryName', 'ProductCategoryName', 'ProductCategoryID']
Getting all query results
The fetchall() method returns a list containing all rows that would be returned by the SQL SELECT statement you executed. Each row instance in the list is a mutable 2, tuple-like object that contains one item for each column selected from the table. See the example below, in which you get all rows from the database.
from pprint import pprint
with conn.cursor() as cursor:
cursor.execute(statement)
headers = [h[0] for h in cursor.description]
rows = cursor.fetchall()
pprint(headers)
pprint(rows)
You would probably not do this in a normal database, which might have thousands or millions of rows. In the AdventureWorks LT sample database that we are using, the vGetAllCategories view contains only a few dozen rows, as seen below:
['ParentProductCategoryName', 'ProductCategoryName', 'ProductCategoryID']
[('Accessories', 'Bike Racks', 30),
('Accessories', 'Bike Stands', 31),
('Accessories', 'Bottles and Cages', 32),
('Accessories', 'Cleaners', 33),
('Accessories', 'Fenders', 34),
('Accessories', 'Helmets', 35),
('Accessories', 'Hydration Packs', 36),
('Accessories', 'Lights', 37),
('Accessories', 'Locks', 38),
('Accessories', 'Panniers', 39),
('Accessories', 'Pumps', 40),
('Accessories', 'Tires and Tubes', 41),
('Clothing', 'Bib-Shorts', 22),
('Clothing', 'Caps', 23),
('Clothing', 'Gloves', 24),
('Clothing', 'Jerseys', 25),
('Clothing', 'Shorts', 26),
('Clothing', 'Socks', 27),
('Clothing', 'Tights', 28),
('Clothing', 'Vests', 29),
('Components', 'Handlebars', 8),
('Components', 'Bottom Brackets', 9),
('Components', 'Brakes', 10),
('Components', 'Chains', 11),
('Components', 'Cranksets', 12),
('Components', 'Derailleurs', 13),
('Components', 'Forks', 14),
('Components', 'Headsets', 15),
('Components', 'Mountain Frames', 16),
('Components', 'Pedals', 17),
('Components', 'Road Frames', 18),
('Components', 'Saddles', 19),
('Components', 'Touring Frames', 20),
('Components', 'Wheels', 21),
('Bikes', 'Mountain Bikes', 5),
('Bikes', 'Road Bikes', 6),
('Bikes', 'Touring Bikes', 7)]
You can iterate through the returned list. Also, each row instance contained in the returned list is like a named tuple, so you can index the returned rows by column name.
For example, to print out only the ParentProductCategoryName and ProductCategoryName columns from the first five rows in the table:
with conn.cursor() as cursor:
cursor.execute(statement)
headers = [h[0] for h in cursor.description]
rows = cursor.fetchall()
print(f'{headers[0]:<27}{headers[1]}')
print('-'*25+' '+'-'*20)
for row in rows[0:5]:
print(f'{row.ParentProductCategoryName:<27}{row.ProductCategoryName}')
The results are shown below:
ParentProductCategoryName ProductCategoryName
------------------------- --------------------
Accessories Bike Racks
Accessories Bike Stands
Accessories Bottles and Cages
Accessories Cleaners
Accessories Fenders
It is convenient to display returned results in a table format. Use the tabulate Python package to display results. You pass it the list of row results and the list containing the column names and it will print out a well-formatted table.
To see all results returned by calling the execute and fetchall() methods, run the following code:
with conn.cursor() as cursor:
cursor.execute(statement)
headers = [h[0] for h in cursor.description]
rows = cursor.fetchall()
print(tabulate(rows, headers=headers))
The formatted table is output as shown below:
ParentProductCategoryName ProductCategoryName ProductCategoryID
--------------------------- --------------------- -------------------
Accessories Bike Racks 30
Accessories Bike Stands 31
Accessories Bottles and Cages 32
Accessories Cleaners 33
Accessories Fenders 34
Accessories Helmets 35
Accessories Hydration Packs 36
Accessories Lights 37
Accessories Locks 38
Accessories Panniers 39
Accessories Pumps 40
Accessories Tires and Tubes 41
Clothing Bib-Shorts 22
Clothing Caps 23
Clothing Gloves 24
Clothing Jerseys 25
Clothing Shorts 26
Clothing Socks 27
Clothing Tights 28
Clothing Vests 29
Components Handlebars 8
Components Bottom Brackets 9
Components Brakes 10
Components Chains 11
Components Cranksets 12
Components Derailleurs 13
Components Forks 14
Components Headsets 15
Components Mountain Frames 16
Components Pedals 17
Components Road Frames 18
Components Saddles 19
Components Touring Frames 20
Components Wheels 21
Bikes Mountain Bikes 5
Bikes Road Bikes 6
Bikes Touring Bikes 7
Read query results in smaller batches
The fetchmany method returns a list containing the number of rows specified by the parameter you pass to it. For example, to get the first four rows available from the SQL query results:
cursor = conn.cursor()
cursor.execute(statement)
headers = [h[0] for h in cursor.description]
rows = cursor.fetchmany(4)
print(tabulate(rows, headers=headers))
The code above prints out the first four rows of the view.
ParentProductCategoryName ProductCategoryName ProductCategoryID
--------------------------- --------------------- -------------------
Accessories Bike Racks 30
Accessories Bike Stands 31
Accessories Bottles and Cages 32
Accessories Cleaners 33
Because you did not use a with block in the code above, the database cursor represented by the cursor instance is still open. You can get the next set of rows from the database simply by running the fethchmany() method again. For example, if you run the following code:
rows = cursor.fetchmany(3)
print(tabulate(rows, headers=headers))
You see a new table printed that shows the next three rows in the database:
ParentProductCategoryName ProductCategoryName ProductCategoryID
--------------------------- --------------------- -------------------
Accessories Fenders 34
Accessories Helmets 35
Accessories Hydration Packs 36
If you keep reading data in batches, you will eventually get to the end of the results. If there are no more results to get, the fetchmany() method returns an empty list.
You may close the cursor now, if you wish:
cursor.close()
And, as shown in the above section about the fetchmany() method, the results of each fetchmany() call are returned as a list of named tuples over which you can iterate.
Read query results one row at a time, or get just one row
The fetchone() method works the similarly as if you used the fetchmany() method and passed it a size parameter of 1. It returns the first row of the database or, if you run it after using the cursor for other fetch operations, it returns the next row in the database. But, since it only reads one row, it returns the row instance by itself and does not store it in a list.
You might use this method along with the skip() method to pick a specific row in the SQL query results. For example, to get the fourth row in the results:
with conn.cursor() as cursor:
cursor.execute(statement)
cursor.skip(3)
print(cursor.fetchone())
This code returns the tuple containing the data from the fourth row in the SQL query results:
('Accessories', 'Cleaners', 33)
Note that the single row instance returned by the fetchone() method is not compatible with the tabulate module because it is not iterable.If you want to use it with tabulate, append it to an empty list and then pass the list to tabulate.
You might also use the fetchone() method in a loop, to perform some additional processing on each row returned by the SQL query. For example, another way to print only the rows that meet a certain condition from the vGetAllCategories view is:
with conn.cursor() as cursor:
cursor.execute("SELECT COUNT (*) FROM SalesLT.vGetAllCategories")
rowcount = cursor.fetchone()[0]
cursor.execute(statement)
for x in range(rowcount):
row = cursor.fetchone()
if row.ParentProductCategoryName == 'Bikes':
print(row.ProductCategoryName)
The above code is just a toy example to show how the fetchone() method might be used in a loop. You would not use code like that in a real program and would, instead, create an SQL statement that filters the ParentProductCategoryName column for the Bikes value and then iterate over the returned rows. The output from running the code above is:
Mountain Bikes
Road Bikes
Touring Bikes
Read one scalar value at a time, or get just one value
The fetchval method will return the value in the first column of the next row available to the cursor. It returns the first value from the first row of the database or, if you run it after using the cursor for other fetch operations, it returns the first value of next row in the database.
Use the fetchval() method when you expect a single scalar result to be returned when you execute your SQL statement. For example, the result of the SQL COUNT function should be a single integer so, instead of using the fetchone() method which returns a tuple-like row object and then getting the result by index as seen in the fetchone() example above, use the fetchval() method as shown below:
with conn.cursor() as cursor:
cursor.execute("SELECT COUNT (*) FROM SalesLT.vGetAllCategories")
rowcount = cursor.fetchval()
print(rowcount)
The output is:
37
SQL Examples
The SQL language is a topic deserving its own study. It is almost as rich and varied in its use as Python. I won't be able to do it justice in a few blog posts so you should consider other resources to learn the details about SQL.
The following examples show some basic SQL statements that you may use to get the data you need from a relational database.
Get all data in a table
The following SQL statement, when executed, should return all columns from all rows in the Product table from the AdventureWorks LT sample database.
statement = """
SELECT *
FROM SalesLT.Product
"""
with conn.cursor() as cursor:
cursor.execute(statement)
headers = [h[0] for h in cursor.description]
rows = cursor.fetchall()
print(tabulate(rows, headers=headers))
This outputs all the columns and rows in the table named Product in the schema named SalesLT. It outputs almost a hundred rows because you used the fetchall() method, which outputs all results available in the cursor instance.
While there are only about three hundred rows in the Product table, the data output is very large because there it has so many columns and one of the columns contains an image file.
NOTE: When a table has large amounts of data and you run the code displayed above in a Jupyter Notebook, the output may exceed the "IOPub data rate" and result in an error. If that happens, stop Jupyterlab and then restart it with an additional setting that sets the IOPub data rate to a higher level, as shown below:
(.venv) $ jupyter-lab --ServerApp.iopub_data_rate_limit 1000000000
Select columns
In the results returned in the example above, you see columns we don't need. For example, the ThumbMailPhoto column contains binary data. The rowguid or ModifiedDate columns are relevant to the database but not useful for data analysis.
Change the T-SQL query statement to select only the columns you are interested in to see less cluttered results. Specify the columns you want to select. In the example below, you will select a subset of the available columns. You can rename columns in the results using the AS statement. See the example below:
statement = """
SELECT
ProductID,
Name,
ProductNumber AS ProdNum,
ProductCategoryID AS CatID,
ProductModelID AS ModID
FROM SalesLT.Product
"""
with conn.cursor() as cursor:
cursor.execute(statement)
headers = [h[0] for h in cursor.description]
rows = cursor.fetchall()
print(tabulate(rows, headers=headers))
The output looks better but it still displays almost three hundred rows:
ProductID Name ProdNum CatID ModID
----------- -------------------------------- ---------- ------- -------
680 HL Road Frame - Black, 58 FR-R92B-58 18 6
706 HL Road Frame - Red, 58 FR-R92R-58 18 6
707 Sport-100 Helmet, Red HL-U509-R 35 33
708 Sport-100 Helmet, Black HL-U509 35 33
709 Mountain Bike Socks, M SO-B909-M 27 18
710 Mountain Bike Socks, L SO-B909-L 27 18
711 Sport-100 Helmet, Blue HL-U509-B 35 33
712 AWC Logo Cap CA-1098 23 2
713 Long-Sleeve Logo Jersey, S LJ-0192-S 25 11
714 Long-Sleeve Logo Jersey, M LJ-0192-M 25 11
...(many more rows)...
Limit the number of rows with the top statement
In some cases, you may want to limit the size of the data selected by your SQL query. You can use the LIMIT T-SQL statement to limit the number of rows that will be available in the cursor instance.
If you use the TOP statement and set the limit to four rows (most other SQL databases use the LIMIT statement), the cursor will return the first four rows of data in the table.
statement = """
SELECT TOP 4
ProductID,
Name,
ProductNumber AS ProdNum,
ProductCategoryID AS CatID,
ProductModelID AS ModID
FROM SalesLT.Product
"""
with conn.cursor() as cursor:
cursor.execute(statement)
headers = [h[0] for h in cursor.description]
rows = cursor.fetchall()
print(tabulate(rows, headers=headers))
In the output, you see that the cursor instance only contains the first four rows. You used the fetchall() method, which returns all rows selected by the T-SQL statement so you know there were only four rows found by the T-SQL query statement.
ProductID Name ProdNum CatID ModID
----------- ------------------------- ---------- ------- -------
680 HL Road Frame - Black, 58 FR-R92B-58 18 6
706 HL Road Frame - Red, 58 FR-R92R-58 18 6
707 Sport-100 Helmet, Red HL-U509-R 35 33
708 Sport-100 Helmet, Black HL-U509 35 33
Combine data from other tables with join statements
You can select data from multiple columns in different tables where there is a relationship between tables. For example, the Product table a column that defines the product category ID, which is an integer, of each product in the table. The ProductCategory table lists the category name that corresponds to each Product Category ID. Similarly, the Product table lists the product model ID for each product and the ProductModel table lists the product model name that corresponds to each product model ID.
If you want the SQL database to return a table containing product information along with the product category name and the product model name, you need to join the Product, ProductCategory, and ProductModel tables and select the columns you need from each.
The following SQL statement will join the tables and select the columns you want:
statement = """
SELECT
ProductID,
Product.Name,
ProductNumber AS ProdNum,
ProductCategory.Name AS Category,
ProductModel.Name AS Model
FROM SalesLT.Product
JOIN SalesLT.ProductCategory
ON Product.ProductCategoryID=ProductCategory.ProductCategoryID
JOIN SalesLT.ProductModel
ON Product.ProductModelID=ProductModel.ProductModelID
"""
with conn.cursor() as cursor:
cursor.execute(statement)
headers = [h[0] for h in cursor.description]
rows = cursor.fetchmany(4)
print(tabulate(rows, headers=headers))
The output is shown below:
ProductID Name ProdNum Category Model
--------- ------------------------- ---------- ----------- -------------
680 HL Road Frame - Black, 58 FR-R92B-58 Road Frames HL Road Frame
706 HL Road Frame - Red, 58 FR-R92R-58 Road Frames HL Road Frame
707 Sport-100 Helmet, Red HL-U509-R Helmets Sport-100
708 Sport-100 Helmet, Black HL-U509 Helmets Sport-100
There are multiple types of joins that determine how rows are selected. The default join is the inner join, which selects only rows where there is a corresponding match. Other types of joins are available in cases where you want to also receive rows that do not match on one side of the join or the other.
Filtering database results
Filter database results using the WHERE statement, which will select rows that match a defined condition. The example below will use the statement we created above, in the join section, then add a filter for rows that have the category name 'Tires and Tubes':
statement = """
SELECT
ProductID,
Product.Name,
ProductNumber AS ProdNum,
ProductCategory.Name AS Category,
ProductModel.Name AS Model
FROM SalesLT.Product
JOIN SalesLT.ProductCategory
ON Product.ProductCategoryID=ProductCategory.ProductCategoryID
JOIN SalesLT.ProductModel
ON Product.ProductModelID=ProductModel.ProductModelID
WHERE ProductCategory.Name = 'Tires and Tubes'
"""
with conn.cursor() as cursor:
cursor.execute(statement)
headers = [h[0] for h in cursor.description]
rows = cursor.fetchall()
print(tabulate(rows, headers=headers))
The output shows only rows that have the matched category name.
ProductID Name ProdNum Category Model
----------- ------------------- --------- --------------- ------------------
873 Patch Kit/8 Patches PK-7098 Tires and Tubes Patch kit
921 Mountain Tire Tube TT-M928 Tires and Tubes Mountain Tire Tube
922 Road Tire Tube TT-R982 Tires and Tubes Road Tire Tube
923 Touring Tire Tube TT-T092 Tires and Tubes Touring Tire Tube
928 LL Mountain Tire TI-M267 Tires and Tubes LL Mountain Tire
929 ML Mountain Tire TI-M602 Tires and Tubes ML Mountain Tire
930 HL Mountain Tire TI-M823 Tires and Tubes HL Mountain Tire
931 LL Road Tire TI-R092 Tires and Tubes LL Road Tire
932 ML Road Tire TI-R628 Tires and Tubes ML Road Tire
933 HL Road Tire TI-R982 Tires and Tubes HL Road Tire
934 Touring Tire TI-T723 Tires and Tubes Touring Tire
You may add operators to the WHERE statement, such as OR and AND and NOT. For example, if you want data related to the categories 'Bikes and Tires, or 'Forks', you would write the following SQL query:
statement = """
SELECT
ProductID,
Product.Name,
ProductNumber AS ProdNum,
ProductCategory.Name AS Category,
ProductModel.Name AS Model
FROM SalesLT.Product
JOIN SalesLT.ProductCategory
ON Product.ProductCategoryID=ProductCategory.ProductCategoryID
JOIN SalesLT.ProductModel
ON Product.ProductModelID=ProductModel.ProductModelID
WHERE ProductCategory.Name = 'Tires and Tubes'
AND NOT ProductModel.Name = 'Patch kit'
OR ProductCategory.Name = 'Forks'
"""
with conn.cursor() as cursor:
cursor.execute(statement)
headers = [h[0] for h in cursor.description]
rows = cursor.fetchall()
print(tabulate(rows, headers=headers))
The output expands to include the category, 'Forks', but leaves out the row where the product model name was 'Patch kit':
ProductID Name ProdNum Category Model
----------- ------------------ --------- --------------- ------------------
802 LL Fork FK-1639 Forks LL Fork
803 ML Fork FK-5136 Forks ML Fork
804 HL Fork FK-9939 Forks HL Fork
921 Mountain Tire Tube TT-M928 Tires and Tubes Mountain Tire Tube
922 Road Tire Tube TT-R982 Tires and Tubes Road Tire Tube
923 Touring Tire Tube TT-T092 Tires and Tubes Touring Tire Tube
928 LL Mountain Tire TI-M267 Tires and Tubes LL Mountain Tire
929 ML Mountain Tire TI-M602 Tires and Tubes ML Mountain Tire
930 HL Mountain Tire TI-M823 Tires and Tubes HL Mountain Tire
931 LL Road Tire TI-R092 Tires and Tubes LL Road Tire
932 ML Road Tire TI-R628 Tires and Tubes ML Road Tire
933 HL Road Tire TI-R982 Tires and Tubes HL Road Tire
934 Touring Tire TI-T723 Tires and Tubes Touring Tire
SQL functions
The SQL func() function has many methods that allow you to run SQL functions on the SQL server. SQL functions may be built in to the SQL server and may also be defined by the database administrator or user.
In the following example, we call SQL Server's built-in COUNT() function to count the number of rows in the table.
statement = """
SELECT COUNT(*)
FROM SalesLT.Product
"""
with conn.cursor() as cursor:
cursor.execute(statement)
result = cursor.fetchval()
print(f'Rows in Product table: {result}')
The output is shown below:
Rows in Product table: 295
To select data from a random sample of five items, run the SQL Server's NEWID() T-SQL function to randomly assign new row IDs, then sort the table by the new row IDs using the ORDER BY statement and select the top five results 3.
Create a statement like the following:
statement = """
SELECT TOP 5
ProductID,
Product.Name,
ProductNumber AS ProdNum,
ProductCategory.Name AS Category,
ProductModel.Name AS Model
FROM SalesLT.Product
JOIN SalesLT.ProductCategory
ON Product.ProductCategoryID=ProductCategory.ProductCategoryID
JOIN SalesLT.ProductModel
ON Product.ProductModelID=ProductModel.ProductModelID
ORDER BY NEWID()
"""
with conn.cursor() as cursor:
cursor.execute(statement)
headers = [h[0] for h in cursor.description]
rows = cursor.fetchall()
print(tabulate(rows, headers=headers))
The random sample of five rows will be printed to the terminal as shown below:
ProductID Name ProdNum Category Model
--------- ------------------------- ---------- --------------- ------------------
839 HL Road Frame - Black, 48 FR-R92B-48 Road Frames HL Road Frame
858 Half-Finger Gloves, S GL-H102-S Gloves Half-Finger Gloves
779 Mountain-200 Silver, 38 BK-M68S-38 Mountain Bikes Mountain-200
934 Touring Tire TI-T723 Tires and Tubes Touring Tire
845 Mountain Pump PU-M044 Pumps Mountain Pump
Every time you execute the T-SQL statement above, you get a different set of data.
Close the database connection
Now that you are done with this tutorial, it is a best-practice to close the database connection. Run the following Python code to close the connection instance you initially created:
conn.close()
Conclusion
I showed how you can use a Python program to read data from an SQL database using the pyodbc library. I also demonstrated SQL SELECT statements that you can use to get the data you need from the database.
Whether you're a data analyst, a software developer, or a curious learner, mastering the art of reading data from an SQL database using Python and pyodbc enable you to extract, transform, and analyze data with ease.
-
Diagram from Microsoft Learning Transact-SQL Exercises and Demonstrations website at https://microsoftlearning.github.io/dp-080-Transact-SQL/ ↩
-
Yes, the Row class instantiates objects that look like named tuples but are mutable. So, keep that in mind when you are using the row instance's attributes in your program. ↩
-
Each version of SQL support different functions. For example, to analyze data from a random sample of items, you use the NEWID() T-SQL function. Other SQL database engines provide functions like RANDOM() or RAND() to get random samples in a more direct fashion. ↩