Explore SQL database schemas with Python
Posted on Thu 18 May 2023 in Databases
This post will show you how to explore your SQL database schema using SQL and the Python pyodbc driver. The examples use Microsoft's SQL Server but the procedures should be usable on any SQL database system.
First steps
This post builds on top of a series of posts I have written. To get the most out of this post, you need to have the following knowledge:
- Basic familiarity with relational databases like SQL databases
- Basic Python skills
You also need to have already prepared a suitable program environment by following the steps outlined in my blog post about creating a sample database server.
- Install Azure CLI and use it to create a database server with a sample database
- Define the necessary environment variables in a dotenv file
- Install the Microsoft SQL Server driver on your Linux PC
- Install the pyodbc driver and the python-dotenv package
After following those instructions, you are ready to start this tutorial.
Install Jupyterlab
You may find it easier to follow this tutorial if you use a Jupyter notebook as an advanced REPL. Using Jupyter Notebooks is optional. If you prefer to use a simple text editor or another REPL, you can still follow along with this tutorial.
I assume you already created a project directory. In my case, I named my project directory data-science-folder. I also assume you created a Python virtual environment in that directory. In my case, I called my virtual environment .venv.
If it is not already active, activate the virtual environment.
$ cd data-science-folder
$ source ./.venv/bin/activate
(.venv) $
To install Jupyterlab in the virtual environment, run the following command:
(.venv) $ pip install jupyterlab
Create a new Jupyter notebook using the command, below:
(.venv) $ jupyter-lab
A new JupyterLab session will open in a browser window.
To use a Jupyter notebook to follow this tutorial, create a new cell in its user interface and then write Python code in the cell. Run the code by running the cell, and view the output. To run the next code example, create a new cell. The objects you create in each cell persist in memory and can be used in the next cell.
If you need more information about using Jupyter Notebooks, read the JupyterLab documentation
Install Tabulate
For convenience, use the tabulate package to format some of your output during this tutorial. To install it, enter the following command:
(.venv) $ pip install tabulate
Check the .env file
You should already have the information needed to create a database connection string. Either you followed the instructions in the previous post about setting up a sample database and got the connection string from Azure, or you asked your database administrator for the valid connection string.
Use the information in the connection string to set up the environment variables you need for database access. See my post about using dotenv files for more details.
For this example, I created a file named .env which assigns the connection string to an environment variable. I pasted in the connection string I got from Azure.
CONN_STRING="Driver={ODBC Driver 18 for SQL Server};Server=tcp:my-sql-server-name.database.windows.net,1433;Database=my-sql-database-name;Uid=my_userid@my-sql-server-name;Pwd=my_password;Encrypt=yes;TrustServerCertificate=no;"
Remember to except your .env file from being tracked in your source control system, if you use one.
Connect to your Database
You can use the pyodbc Python library to connect to, and read data from, an SQL Server database. Create a connection object by passing the connection string to the pyodbc driver's connect() function.
import pyodbc
import os
from dotenv import load_dotenv
load_dotenv('.env', override=True)
connection_string = os.getenv('CONN_STRING')
conn = pyodbc.connect(connection_string)
print(conn)
You should see the connection information in the output. It should look like the following:
<pyodbc.Connection object at 0x0000014F5D0C1CA0>
Explore the database schema
Tou need information about the data model configured in the database. For example, you want to know what schemas are available, the tables and views in each schema, the columns in each table or view and the type of data stored in each column, and the data relationships between tables.
Normally, you get this information from the database documentation. If no documentation is available, you can analyze the database with an SQL discovery tool like SchemaSpy, SchemaCrawler. You can also write a Python program to analyze the database schema information, which is what we will do in this post.
Get database information
The first thing you need to know is what database schemas exist on the server. To get a list of all schema supported in the database, use the cursor.tables() method and filter the results for distinct schema names.
Run the following Python code to get that information:
cursor = conn.cursor()
schema_set = set()
for row in cursor.tables():
schema_set.add(row.table_schem)
print('Schema Name')
print('-' * 11)
print(*schema_set, sep='\n')
cursor.close()
The code you ran will print out the following output:
Schema Name
-----------
SalesLT
dbo
INFORMATION_SCHEMA
sys
You used the results returned from the cursor object's tables() method to get all schemas and tables in the database.
Most SQL servers keep their database system information in a schema named INFORMATION_SCHEMA. This is a standard for SQL servers, but not every SQL database implements the standard. Querying the INFORMATION_SCHEMA tables is the "general" method of getting SQL database schema information.
NOTE: You can get a lot of database information using the cursor object's methods. I will discuss it, along with the database system tables 1, in Appendix A at the end of this post.
To use the pyodbc Python library to analyze database information, craft SQL SELECT statements that query database information and run them with the cursor's execute() method. Read the Microsoft T-SQL documentation to learn how the Microsoft SQL Server implements the INFORMATION_SCHEMA schema and how to write T-SQL statements that get information from it.
Get schema names
Create a Microsoft Transact-SQL (T-SQL) 2 statement that selects the TABLE_SCHEMA column in the TABLES table in the INFORMATION_SCHEMA schema, and sorts the returned data alphabetically:
Execute the statement using the cursor's execute() function. This places the data results in the cursor. You can get all the results at once using the cursor object's fetchall() method.
statement = """
SELECT DISTINCT
TABLE_SCHEMA
FROM INFORMATION_SCHEMA.TABLES
ORDER BY TABLE_SCHEMA
"""
cursor = conn.cursor()
cursor.execute(statement)
print(cursor.fetchall())
cursor.close()
The cursor.fetchall() statement returns a list containing database schemas that you have permission to read.
[('dbo',), ('SalesLT',), ('sys',)]
Table and views names in a schema
The dbo and sys schemas are used by SQL Server for system information. To get the SalesLT schema's table name information from the INFORMATION_SCHEMA.TABLES table, create the following SQL statement and then execute it.
from tabulate import tabulate
statement = """
SELECT
TABLE_NAME, TABLE_TYPE
FROM INFORMATION_SCHEMA.TABLES
WHERE TABLE_SCHEMA = 'SalesLT'
ORDER BY TABLE_NAME
"""
with conn.cursor() as cursor:
cursor.execute(statement)
headers = [h[0] for h in cursor.description]
tables = cursor.fetchall()
print(tabulate(tables, headers=headers))
The output contains table and view names in the SalesLT schema.
TABLE_NAME TABLE_TYPE
------------------------------- ------------
Address BASE TABLE
Customer BASE TABLE
CustomerAddress BASE TABLE
Product BASE TABLE
ProductCategory BASE TABLE
ProductDescription BASE TABLE
ProductModel BASE TABLE
ProductModelProductDescription BASE TABLE
SalesOrderDetail BASE TABLE
SalesOrderHeader BASE TABLE
vGetAllCategories VIEW
vProductAndDescription VIEW
vProductModelCatalogDescription VIEW
You can see there are ten tables and three views in the SalesLT schema.
Column names in a table
Finally, we need the list of columns in each table we plan to use, along with some of their attributes.
Get the column name information from the INFORMATION_SCHEMA.COLUMNS table. Then filter on the SalesLT schema and the table name to create the following SQL statement and execute it.
Since we'll use this code for each table, you should define a function, as shown below:
def table_info(table, schema='SalesLT'):
statement = (
f"SELECT COLUMN_NAME, DATA_TYPE, CHARACTER_MAXIMUM_LENGTH\n"
f"FROM INFORMATION_SCHEMA.COLUMNS\n"
f"WHERE TABLE_SCHEMA = '{schema}'\n"
f"AND TABLE_NAME = '{table}'"
)
with conn.cursor() as cursor:
cursor.execute(statement)
headers = [h[0] for h in cursor.description]
table_rows = cursor.fetchall()
return table_rows, headers
Then, call the function for each table in the SalesLT schema. For example, to see all the columns in the Address table:
table, head = table_info('Address')
print(tabulate(table, headers=head))
The output contains name, type, and length of each column in the Address table.
COLUMN_NAME DATA_TYPE CHARACTER_MAXIMUM_LENGTH
------------- ---------------- --------------------------
AddressID int
AddressLine1 nvarchar 60
AddressLine2 nvarchar 60
City nvarchar 30
StateProvince nvarchar 50
CountryRegion nvarchar 50
PostalCode nvarchar 15
rowguid uniqueidentifier
ModifiedDate datetime
Continue until you have the column information for each table. You may also want to see what data is available in the views. For example, to see the columns in the vProductAndDescription view, run the following code:
table, head = table_info('vProductAndDescription')
print(tabulate(table, headers=head))
You will see the column information as shown below:
COLUMN_NAME DATA_TYPE CHARACTER_MAXIMUM_LENGTH
------------- ----------- --------------------------
ProductID int
Name nvarchar 50
ProductModel nvarchar 50
Culture nchar 6
Description nvarchar 400
Table constraints
Normally, database tables are defined with constraints such as a primary key and foreign keys. The primary key, foreign keys, and other constrains define relationships between tables in a relational database. Create a function that gets constraint data for a table:
def constraint_info(table, schema='SalesLT'):
statement = f"""
SELECT
TABLE_NAME,
CONSTRAINT_NAME,
CONSTRAINT_TYPE
FROM INFORMATION_SCHEMA.TABLE_CONSTRAINTS
WHERE TABLE_SCHEMA = '{schema}'
AND TABLE_NAME = '{table}'
AND (CONSTRAINT_TYPE = 'FOREIGN KEY'
OR CONSTRAINT_TYPE = 'PRIMARY KEY')
"""
with conn.cursor() as cursor:
cursor.execute(statement)
headers = [h[0] for h in cursor.description]
constraint_rows = cursor.fetchall()
return constraint_rows, headers
For the purpose of joining tables so we can read data, we are interested in the primary keys and foreign keys. Other types of keys are important if we plan to write or delete data in the database but I am only discussing how we read data in this post.
Get the Address view's primary and foreign key constraints with the following code:
table, head = constraint_info('Address')
print(tabulate(table, headers=head))
The constraints defined for the Address table are output below:
TABLE_NAME CONSTRAINT_NAME CONSTRAINT_TYPE
------------ -------------------- -----------------
Address PK_Address_AddressID PRIMARY KEY
Repeat the process for each table until all constrains are recorded. For example, get the Product table's constraints:
table, head = constraint_info('Product')
print(tabulate(table, headers=head))
The Product table's constraints are:
TABLE_NAME CONSTRAINT_NAME CONSTRAINT_TYPE
------------ -------------------------------------------- -----------------
Product FK_Product_ProductCategory_ProductCategoryID FOREIGN KEY
Product FK_Product_ProductModel_ProductModelID FOREIGN KEY
Product PK_Product_ProductID PRIMARY KEY
You can see the foreign keys that point to the Product table but you do not know to which table and column they point, although you can infer that information because the database administrator chose descriptive constraint names. Another, more complex T-SQL query can tell us all the foreign keys 3 in the database and to which table the foreign keys point:
def pk_fk_info():
statement = f"""
SELECT
KCU1.TABLE_NAME AS 'FK_TABLE_NAME',
KCU1.COLUMN_NAME AS 'FK_COLUMN_NAME',
KCU2.TABLE_NAME AS 'UQ_TABLE_NAME',
KCU2.COLUMN_NAME AS 'UQ_COLUMN_NAME'
FROM INFORMATION_SCHEMA.REFERENTIAL_CONSTRAINTS RC
JOIN INFORMATION_SCHEMA.KEY_COLUMN_USAGE KCU1
ON KCU1.CONSTRAINT_CATALOG = RC.CONSTRAINT_CATALOG
AND KCU1.CONSTRAINT_SCHEMA = RC.CONSTRAINT_SCHEMA
AND KCU1.CONSTRAINT_NAME = RC.CONSTRAINT_NAME
JOIN INFORMATION_SCHEMA.KEY_COLUMN_USAGE KCU2
ON KCU2.CONSTRAINT_CATALOG = RC.UNIQUE_CONSTRAINT_CATALOG
AND KCU2.CONSTRAINT_SCHEMA = RC.UNIQUE_CONSTRAINT_SCHEMA
AND KCU2.CONSTRAINT_NAME = RC.UNIQUE_CONSTRAINT_NAME
AND KCU2.ORDINAL_POSITION = KCU1.ORDINAL_POSITION
ORDER BY FK_TABLE_NAME
"""
with conn.cursor() as cursor:
cursor.execute(statement)
headers = [h[0] for h in cursor.description]
constraint_rows = cursor.fetchall()
return constraint_rows, headers
table, head = pk_fk_info()
print(tabulate(table, headers=head))
The output shows all foreign keys in each table and the keys to which they point:
FK_TABLE_NAME FK_COLUMN_NAME UQ_TABLE_NAME UQ_COLUMN_NAME
--------------- ----------------------- ---------------- -----------------
CustomerAddress AddressID Address AddressID
CustomerAddress CustomerID Customer CustomerID
Product ProductCategoryID ProductCategory ProductCategoryID
Product ProductModelID ProductModel ProductModelID
ProductCategory ParentProductCategoryID ProductCategory ProductCategoryID
...
SalesOrderDetail ProductID Product ProductID
SalsOrderDetail SalesOrderID SalesOrderHeader SalesOrderID
SalsOrderHeader BillToAddressID Address AddressID
SalsOrderHeader ShipToAddressID Address AddressID
SalsOrderHeader CustomerID Customer CustomerID
Get view definitions
When working with data in a large company, your access to databases may always be through views, instead of tables. Database administrators and data owners use views as a way to provide clients with the data they need, without exposing data the client does not need. A database view is like a "saved query" that run when you select columns from it.
You may need to know what data is included in a database view. For example, what tables are joined and are any rows filtered? You can see the view definition in the INFORMATION_SCHEMA.VIEWS table.
Create a function that will return the view definition:
def view_def(view, schema='SalesLT'):
statement = (
f"SELECT VIEW_DEFINITION\n"
f"FROM INFORMATION_SCHEMA.VIEWS\n"
f"WHERE TABLE_SCHEMA = '{str(schema)}'\n"
f"AND TABLE_NAME = '{str(view)}'"
)
view_definition = str()
with conn.cursor() as cursor:
cursor.execute(statement)
for row in cursor.fetchone():
view_definition = view_definition + row + '\n'
return view_definition
Then, print the view definition for each view in the database. For example, to see the vProductAndDescription view definition:
print(view_def('vProductAndDescription'))
This will display the view definition for the vProductAndDescription view, which is the T-SQL statement that would generate the same data as the selecting the view.
CREATE VIEW [SalesLT].[vProductAndDescription]
WITH SCHEMABINDING
AS
-- View (indexed or standard) to display products and product descriptions by language.
SELECT
p.[ProductID]
,p.[Name]
,pm.[Name] AS [ProductModel]
,pmx.[Culture]
,pd.[Description]
FROM [SalesLT].[Product] p
INNER JOIN [SalesLT].[ProductModel] pm
ON p.[ProductModelID] = pm.[ProductModelID]
INNER JOIN [SalesLT].[ProductModelProductDescription] pmx
ON pm.[ProductModelID] = pmx.[ProductModelID]
INNER JOIN [SalesLT].[ProductDescription] pd
ON pmx.[ProductDescriptionID] = pd.[ProductDescriptionID];
If you look for constraints in one of the views, you will notice that the database views do not have constraints. This is normal for views, which are not typically joined with other tables to create data sets. For example, get the vProductAndDescription view constraints information:
table, head = constraint_info('vProductAndDescription')
print(table)
Outputs an empty list:
[]
Map the database relationships
Use the information you have gathered to draw a database diagram. Foreign keys in each table should point to primary keys in other tables. The AdventureWorksLT database diagram will look like the following 4:
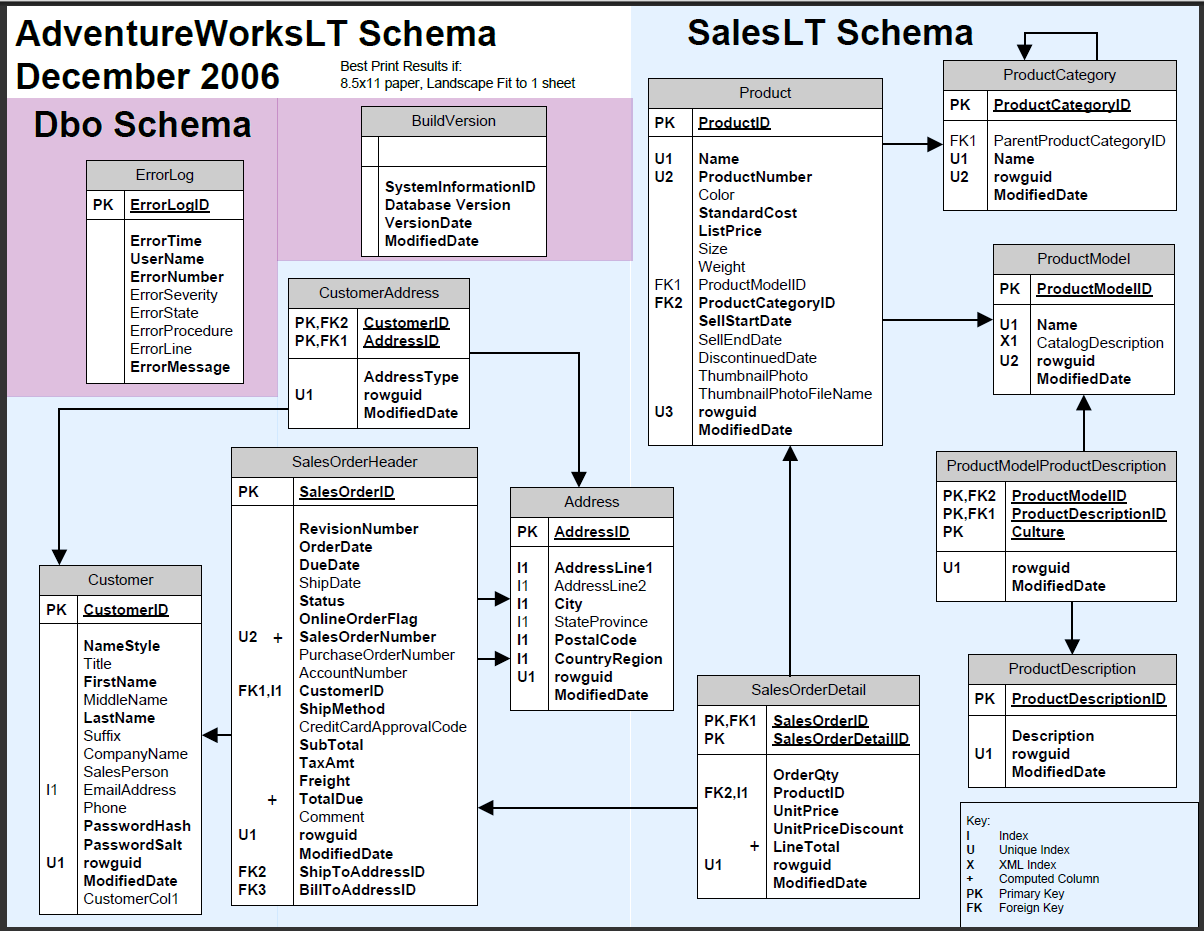
Conclusion
You used Python functions to read the schema information of the Microsoft AdventureWorks database on an SQL Server. You used the INFORMATION_SCHEMA schema to get the database information so hopefully the functions we wrote can also be used on other SQL database servers.
You are now ready to start reading data from the database and analyzing it. I'll explore that topic in a future post.
Appendix A: Alternative ways to get database schema information
There are multiple ways to get database schema information in a Python program. In the main body of this document, we covered the most universal method.
I found that the reading from cursor methods was easy and felt more "Pythonic" but you cannot query data from the database using just the cursor methods, so it is probably best to learn how to use SQL Query statements to get the database schema information so you get more practice using SQL. For your information, I cover using cursor methods in this appendix. I also provide an example of querying the database system tables to get database schema information.
Read database information from the cursor instance
A cursor object is instantiated when you call the pyodbc connection's cursor() method. You do not need to know how to write SQL statements when using the cursor object and it offers many methods and attributes that describe the database details. But, the cursor object lists all database elements, even those that you do not have permission to access.
Schema names
Create an instance of the pyodbc cursor. Then, iterate through all tables in the object returned by the cursor's tables() method.
with conn.cursor() as cursor:
for row in cursor.tables():
print(row)
This lists all tables and views in a database. You see 519 rows listed. The available schemas are in the output's second column.
('data-science-test', 'dbo', 'BuildVersion', 'TABLE', None)
('data-science-test', 'dbo', 'ErrorLog', 'TABLE', None)
('data-science-test', 'SalesLT', 'Address', 'TABLE', None)
('data-science-test', 'SalesLT', 'Customer', 'TABLE', None)
('data-science-test', 'SalesLT', 'CustomerAddress', 'TABLE', None)
('data-science-test', 'SalesLT', 'Product', 'TABLE', None)
('data-science-test', 'SalesLT', 'ProductCategory', 'TABLE', None)
('data-science-test', 'SalesLT', 'ProductDescription', 'TABLE', None)
('data-science-test', 'SalesLT', 'ProductModel', 'TABLE', None)
('data-science-test', 'SalesLT', 'ProductModelProductDescription', 'TABLE', None)
('data-science-test', 'SalesLT', 'SalesOrderDetail', 'TABLE', None)
('data-science-test', 'SalesLT', 'SalesOrderHeader', 'TABLE', None)
('data-science-test', 'sys', 'trace_xe_action_map', 'TABLE', None)
('data-science-test', 'sys', 'trace_xe_event_map', 'TABLE', None)
('data-science-test', 'INFORMATION_SCHEMA', 'CHECK_CONSTRAINTS', 'VIEW', None)
('data-science-test', 'INFORMATION_SCHEMA', 'COLUMN_DOMAIN_USAGE', 'VIEW', None)
...
A more elegant way to list just the available schema names is to filter using a set, as shown below:
schema_set = set()
with conn.cursor() as cursor:
for row in cursor.tables():
schema_set.add(row.table_schem)
print(schema_set)
This outputs a set of the available schema:
{'INFORMATION_SCHEMA', 'dbo', 'SalesLT', 'sys'}
Table and views names in a schema
To list table and views names in a schema, use the cursor object's tables() method again but pass it a schema parameter so it lists only tables and views from the schema you are interested in exploring. In this example, you will generate a list of views in the SalesLT schema.
from tabulate import tabulate
with conn.cursor() as cursor:
tables = cursor.tables(schema='SalesLT').fetchall()
headers = [h[0] for h in cursor.description]
print(tabulate(tables, headers=headers))
In this example, we wanted the table name from each row. We knew that the tables names were in the third column so we iterated through each row and generated the output seen below:
table_cat table_schem table_name table_type remarks
----------------- ------------- ------------------------------- ------------ ---------
data-science-test SalesLT Address TABLE
data-science-test SalesLT Customer TABLE
data-science-test SalesLT CustomerAddress TABLE
data-science-test SalesLT Product TABLE
data-science-test SalesLT ProductCategory TABLE
data-science-test SalesLT ProductDescription TABLE
data-science-test SalesLT ProductModel TABLE
data-science-test SalesLT ProductModelProductDescription TABLE
data-science-test SalesLT SalesOrderDetail TABLE
data-science-test SalesLT SalesOrderHeader TABLE
data-science-test SalesLT vGetAllCategories VIEW
data-science-test SalesLT vProductAndDescription VIEW
data-science-test SalesLT vProductModelCatalogDescription VIEW
Column names in a table
Use the cursor.columns() method to get a list of table information and pass it a table or view name and a schema name.
In this example, choose the table named Address from the SalesLT schema. Use the cursor.columns() method to get a list of table information. In the example below, you get the headers for the returned information from the cursor.description attribute. The column name, type, and size are in the fourth, sixth, and seventh column of the returned results.
def column_info(table, schema='SalesLT'):
column_list = []
indexes = (3,5,6)
with conn.cursor() as cursor:
for row in cursor.columns(table=table, schema=schema):
column_data = [row[x] for x in indexes]
column_list.append(column_data)
headers = [cursor.description[x][0] for x in indexes]
return column_list, headers
columns, headers = column_info('Address')
print(tabulate(columns, headers))
The output displays column information.
column_name type_name column_size
------------- ---------------- -------------
AddressID int identity 10
AddressLine1 nvarchar 60
AddressLine2 nvarchar 60
City nvarchar 30
StateProvince Name 50
CountryRegion Name 50
PostalCode nvarchar 15
rowguid uniqueidentifier 36
ModifiedDate datetime 23
Table constraints
Normally, database tables are defined with constraints such as a primary key and foreign keys.
Create functions that use the cursor object's primaryKeys() and foreignKeys() methods to determine if any columns in the table are primary keys or foreign keys.
def constraint_info(table, schema='SalesLT'):
pk_list = []
fk_list = []
pk_headers = []
fk_headers = []
pk_indexes = (3, )
fk_indexes= (3, 6, 7)
with conn.cursor() as cursor:
for row in cursor.primaryKeys(table=table, schema=schema):
data = [row[x] for x in pk_indexes]
pk_list.append(data)
pk_headers = [cursor.description[x][0] for x in pk_indexes]
for row in cursor.foreignKeys(table=table, schema=schema):
data = [row[x] for x in fk_indexes]
fk_list.append(data)
fk_headers = [cursor.description[x][0] for x in fk_indexes]
return pk_list, pk_headers, fk_list, fk_headers
def display_constraints(table, schema='SalesLT'):
pk_list, pk_headers, fk_list, fk_headers = constraint_info(table)
output = ''
output += f'TABLE = {schema}.{table}\n'
output += '=========================\n'
output += '\n'
output += 'Primary Keys\n'
output += tabulate(pk_list, headers=pk_headers) + '\n'
output += '\n'
output += 'Foreign Keys\n'
output += tabulate(fk_list, headers=fk_headers)
return output
Use the functions to get constrain information about each table.
table = 'Address'
print(display_constraints(table))
You will see that primary and foreign keys associated with the Address table
TABLE = SalesLT.Address
=========================
Primary Keys
column_name
-------------
AddressID
Foreign Keys
pkcolumn_name fktable_name fkcolumn_name
--------------- ---------------- ---------------
AddressID CustomerAddress AddressID
AddressID SalesOrderHeader BillToAddressID
AddressID SalesOrderHeader ShipToAddressID
Get data from the system tables
Another way to get database information is to query the sys.objects catalog view in the Microsoft SQL Server database. The sys.objects table is not a standard and may have different columns in different database systems.
While Microsoft recommends using it, I find the sys tables hard to use for SQL beginners. Getting the information you need from the sys tables requires a deep knowledge of T-SQL and SQL Server. Otherwise, you will end up like me, trolling through StackOverflow for T-SQL recipes.
Schema names
The T-SQL statement below 5 finds all the schema IDs in the sys.objects view and then finds their schema names in the sys.schema table by joining on the schema ID.
statement = """
SELECT DISTINCT sys.schemas.name AS schema_name
FROM sys.objects
INNER JOIN sys.schemas ON sys.objects.schema_id = sys.schemas.schema_id
ORDER BY schema_name
"""
with conn.cursor() as cursor:
cursor.execute(statement)
schema_list = cursor.fetchall()
print(schema_list)
The schema information is the same as was gathered from the INFORMATION_SCHEMA.VIEWS table.
[('dbo',), ('SalesLT',), ('sys',)]
Table and views names in a schema
To get the table name information from the sys.objects catalog view, create the following SQL statement and then execute it.
statement = """
SELECT sys.objects.name AS table_name
FROM sys.objects
INNER JOIN sys.schemas ON sys.objects.schema_id = sys.schemas.schema_id
WHERE sys.schemas.name = 'SalesLT'
AND sys.objects.type = 'U' OR sys.objects.type = 'V'
"""
with conn.cursor() as cursor:
cursor.execute(statement)
for row in cursor.fetchall():
print(*row)
The output contains table and view names in the employment_details schema.
database_firewall_rules
Customer
ProductModel
vProductModelCatalogDescription
ProductDescription
Product
ProductModelProductDescription
vProductAndDescription
ProductCategory
vGetAllCategories
Address
CustomerAddress
SalesOrderDetail
SalesOrderHeader
Column names in a table
To get the column name information from the sys.objects catalog view, create the following function 6.
def columns_info(table, schema='SalesLT'):
statement = f"""
SELECT
sys.columns.name as column_name,
sys.types.name as type,
sys.columns.max_length as max_length
FROM sys.objects
JOIN sys.columns
ON sys.objects.object_id = sys.columns.object_id
INNER JOIN sys.types
ON sys.types.user_type_id = sys.columns.user_type_id
INNER JOIN sys.schemas
ON sys.objects.schema_id = sys.schemas.schema_id
WHERE sys.objects.name = '{table}'
AND sys.schemas.name = '{schema}'
"""
with conn.cursor() as cursor:
cursor.execute(statement)
headers = [h[0] for h in cursor.description]
results = cursor.fetchall()
return results, headers
Then get the columns from the Address table:
results, headers = columns_info('Address')
print(tabulate(results, headers=headers))
The output contains name, type, and length of each column in the Address table.
column_name type max_length
------------- ---------------- ------------
AddressID int 4
AddressLine1 nvarchar 120
AddressLine2 nvarchar 120
City nvarchar 60
StateProvince Name 100
CountryRegion Name 100
PostalCode nvarchar 30
rowguid uniqueidentifier 16
ModifiedDate datetime 8
Table primary keys
To get information about constraints such as a primary key, query tables in the sys schema with the following code. 7 The example below asks for constraint information in the table named Address.
def pk_info(table, schema='SalesLT'):
statement = f"""
SELECT
sys.columns.name AS column_name,
sys.indexes.name AS index_name,
sys.columns.is_identity
FROM sys.indexes
inner join sys.index_columns
ON sys.indexes.object_id = sys.index_columns.object_id
AND sys.indexes.index_id = sys.index_columns.index_id
inner join sys.columns
ON sys.index_columns.object_id = sys.columns.object_id
AND sys.columns.column_id = sys.index_columns.column_id
WHERE sys.indexes.is_primary_key = 1
and sys.indexes.object_ID = OBJECT_ID('{schema}.{table}');
"""
with conn.cursor() as cursor:
cursor.execute(statement)
headers = [h[0] for h in cursor.description]
results = cursor.fetchall()
return results, headers
results, headers = pk_info('Address')
print(tabulate(results, headers=headers))
This outputs shows all the primary keys for the table Address.
column_name index_name is_identity
------------- -------------------- -------------
AddressID PK_Address_AddressID True
You can repeat this for every table. For example, get the Primary keys from the CustomerAddress table:
results, headers = pk_info('CustomerAddress')
print(tabulate(results, headers=headers))
You can see in the results below that the CustomerAddress table is probably an association tabl that supports a many-to-many relationship between other tables, because the primary keys are not identifier and, when we look at foreign keys we will probably see that both primary keys are also foreign keys.
column_name index_name is_identity
------------- --------------------------------------- -------------
CustomerID PK_CustomerAddress_CustomerID_AddressID False
AddressID PK_CustomerAddress_CustomerID_AddressID False
Table foreign keys
Write the following function 8 to get the foreign keys from any table:
def fk_info(table, schema='SalesLT'):
statement = f"""
SELECT
tab1.name AS table_name,
col1.name AS column_name,
tab2.name AS referenced_table,
col2.name AS referenced_column
FROM sys.foreign_key_columns fkc
INNER JOIN sys.objects obj
ON obj.object_id = fkc.constraint_object_id
INNER JOIN sys.tables tab1
ON tab1.object_id = fkc.parent_object_id
INNER JOIN sys.schemas sch
ON tab1.schema_id = sch.schema_id
INNER JOIN sys.columns col1
ON col1.column_id = parent_column_id AND col1.object_id = tab1.object_id
INNER JOIN sys.tables tab2
ON tab2.object_id = fkc.referenced_object_id
INNER JOIN sys.columns col2
ON col2.column_id = referenced_column_id AND col2.object_id = tab2.object_id
WHERE sch.name = '{schema}' AND tab1.name = '{table}'
"""
with conn.cursor() as cursor:
cursor.execute(statement)
headers = [h[0] for h in cursor.description]
results = cursor.fetchall()
return results, headers
Use the function to get the foreign keys from the CustomerAddress table:
results, headers = fk_info('CustomerAddress')
print(tabulate(results, headers=headers))
The output shows that the foreign keys in the CustomerAddress table are the same as its primary keys. Which means this table is probably an association table.
table_name column_name referenced_table referenced_column
--------------- ------------- ------------------ -------------------
CustomerAddress CustomerID Customer CustomerID
CustomerAddress AddressID Address AddressID
-
Microsoft's SQL Server documentation states that the more reliable way to gather information is to query the sys.objects catalog view because the INFORMATION_SCHEMA schema contains only a subset of database information. But, I found the INFORMATION_SCHEMA tables to be simpler to use and to contain all the information I needed for this tutorial. ↩
-
Microsoft Transact-SQL, also known as T-SQL, is Microsoft SQL Server's version of the SQL language. ↩
-
The T-SQL statement was taken from https://learn.microsoft.com/en-us/previous-versions/sql/legacy/aa175805(v=sql.80) ↩
-
Diagram from http://shaneryan81.blogspot.com/2015/08/adventureworks-2012-lt-schema.html ↩
-
T-SQL statement from StackOverflow answer reference# 917431: SQL Server - Return SCHEMA for sysobjects (917431) ↩
-
T-SQL statement from Stackoverflow answer reference# 9179990:Where do I find Sql Server metadata for column datatypes? ↩
-
T-SQL statement from Stackoverflow answer reference# 95967: How do you list the primary key of a SQL Server table? ↩
-
T-SQL statement taken from StackOverflow answer reference# 483193: How can I list all foreign keys referencing a given table in SQL Server? ↩