Explore relational database schemas with SQLAlchemy
Posted on Wed 16 August 2023 in Databases
One way to learn about the structure of an existing database is to use the SQLAlchemy inspection module. It provides a simple interface to read database schema information via a Python API.
This post provides inspection examples that are relevant to users who read and analyze data, and who need to understand the relationships within a database.
Set up the environment.
Create a Python virtual environment for you Python program. Install the psycopg2 Postgres database adapter, the SQLAlchemy framework, Pandas, and tabulate.
$ mkdir Project
$ cd Project
$ python3 -m venv .venv
$ source .venv/bin/activate
(.venv) $ pip install wheel
(.venv) $ pip install psycopg2
(.venv) $ pip install sqlalchemy
(.venv) $ pip install pandas
(.venv) $ pip install tabulate
In this post, I create a container running the Chinook sample database on a PostgreSQL server. I described how I created a local Docker image named postgres-chinook-image in my previous post.
$ docker run \
--detach \
--env POSTGRES_PASSWORD=abcd1234 \
--network host \
--name chinook1\
postgres-chinook-image
Create an instance of the Inspector class
In your the Python REPL, or in a Jupyter notebook, write the following code to establish a connection to the database and generate an SQLAlchemy engine object.
from sqlalchemy.engine import URL
from sqlalchemy import create_engine
url_object = URL.create(
drivername='postgresql+psycopg2',
username='postgres',
password='abcd1234',
host='localhost',
port='5432',
database='chinook')
engine = create_engine(url_object)
Create an Inspector instance using SQLAlchemy's inspect() function.
from sqlalchemy import inspect
insp = inspect(engine)
You created a new Inspector instance, named insp, that contains all the information you need about the structure of the database managed by the engine object.
Inspector methods
An instance of the Inspector class has many methods that can be used to display database information. The methods and attributes covered in this post are listed below:
- get_schema_names()
- default_schema_name
- get_table_names()
- get_columns()
- get_pk_constraint()
- get_foreign_keys()
- get_view_names()
Schema names
Databases typical have multiple schemas. List all schemas in the database using the Inspector instance's get_schema_names() method:
print(insp.get_schema_names())
The output shows a list of the public and information_schema schemas.
['information_schema', 'public']
You can see the default schema name by checking the value of the default_schema_name attribute:
print(insp.default_schema_name)
You should see that the default schema is public:
public
Table names
Use the Inspector instance's get_table_names() method to list the tables in the schema.
print("Tables in 'public' schema:")
print(insp.get_table_names('public'))
print()
print("Tables in 'information_schema' schema:")
print(insp.get_table_names('information_schema'))
We see the tables related to the Chinook media store are in the public schema and that some system tables are in the information_schema schema:
Tables in 'public' schema:
['Artist', 'Album', 'Employee', 'Customer', 'Invoice', 'InvoiceLine', 'Track', 'Playlist', 'PlaylistTrack', 'Genre', 'MediaType']
Tables in 'information_schema' schema:
['sql_features', 'sql_implementation_info', 'sql_parts', 'sql_sizing']
View names
Use the Inspector instance's get_view_names() method to list views defined in the database.
print(insp.get_view_names(schema='public'))
Since there are no views in the Chinook sample database, this method returns an empty list.
[]
Column details
When the Inspector instance's methods return iterables, you can use Python's "pretty print" module, pprint, to display inspection in a manner that is easier to read. To see details about a table's columns and primary key, enter the following code:
from pprint import pprint
pprint(insp.get_columns(table_name="Album",schema="public"))
When you run the code, you see that the get_columns() method returns a list. Each item in the list is a dictionary that contains information about a column in the Album table.
[{'autoincrement': False,
'comment': None,
'default': None,
'name': 'AlbumId',
'nullable': False,
'type': INTEGER()},
{'autoincrement': False,
'comment': None,
'default': None,
'name': 'Title',
'nullable': False,
'type': VARCHAR(length=160)},
{'autoincrement': False,
'comment': None,
'default': None,
'name': 'ArtistId',
'nullable': False,
'type': INTEGER()}]
It's important to know that, while SQLAlchemy abstracts away the details of an SQL relational database, each database dialect returns information differently. So, don't build a program that only works if the objects returned by the get_columns() look exactly like those above. For example, the same Chinook database running in SQL Server returns additional information about primary keys in the results, but PostgreSQL does not.
Private keys
To see the private key, or keys, of a table, use the get_pk_constraint() method:
print(insp.get_pk_constraint(table_name="Album",schema="public"))
You see the get_pk_constraint() method returns a dictionary containing a list of the table's primary keys.
{'constrained_columns': ['AlbumId'], 'name': 'PK_Album', 'comment': None}
In this case, the Album table's primary key is the AlbumId column.
Foreign keys
To see which columns in a table are foreign keys, use the get_foreign_keys() method:
pprint(insp.get_foreign_keys(table_name="Album",schema="public"))
You can see in the output below that the Album table's ArtistId column is a foreign key that points to the ArtistId column in the Artist table:
[{'comment': None,
'constrained_columns': ['ArtistId'],
'name': 'FK_AlbumArtistId',
'options': {},
'referred_columns': ['ArtistId'],
'referred_schema': None,
'referred_table': 'Artist'}]
Note that the referred_schema is "None" because the SQL script that created teh Chinook database did not specify the schema. So PostgreSQL build the tables in the default schema, which is the public schema.
Other constraints
You may inspect more complex SQLAlchemy relationship constraints like the constraints that are relevant to users who want to update or delete information in a database, such as unique constraints. I am currently focused on reading and analyzing data so I will not cover other types of relationships in this post. See the SQLAlchemy Inspect documentation for more ways to use the SQLAlchemy inspection module.
Gathering table relationship information
To gather all the information you need about table relationships to build a database diagram, write a Python function named inspect_relationships() that read a table's columns and relationships by iterating through the Inspector instance's attributes. Enter the code shown below:
def inspect_relationships(table_name):
tbl_out = f"Table = {table_name}\n"
col_out = "Columns = "
cols_list = insp.get_columns(table_name)
for i, c in enumerate(cols_list, 1):
if i < len(cols_list):
col_out += (c['name'] + ", ")
else:
col_out += c['name'] + "\n"
pk_out = "Primary Keys = "
pk = insp.get_pk_constraint(table_name)
pk_list = pk["constrained_columns"]
for i, c in enumerate(pk_list):
if i < len(pk_list) - 1:
pk_out += (c + ", ")
else:
pk_out += (c + "\n")
fk_out = ""
fk_list = insp.get_foreign_keys(table_name)
if fk_list:
fk_out = "Foreign Keys:\n"
fk_name_list = []
fk_reftbl_list = []
fk_refcol_list = []
for fk in fk_list:
fk_name_list.append(*fk['constrained_columns'])
fk_reftbl_list.append(fk['referred_table'])
fk_refcol_list.append(*fk['referred_columns'])
fk_info = zip(fk_name_list, fk_reftbl_list, fk_refcol_list)
for n, t, c in fk_info:
fk_out += f" {n} ---> {t}:{c}\n"
return("".join([tbl_out, col_out, pk_out, fk_out]))
Use the inspect_relationships() function to print table relationship information by passing it a table name. The function returns the table information as a long string.
You can get information about one table by passing it a table name, as shown below:
print(inspect_relationships("Album"))
The function returns the table information as a long string:
Table = Album
Columns = Title, ArtistId, AlbumId
Primary Keys = AlbumId
Foreign Keys:
ArtistId ---> Artist:ArtistId
you can see all tables in a database by iterating through the list returned by the Inspector instance's get_table_names() method, as shown below.
for tbl in insp.get_table_names():
print(inspect_relationships(tbl))
The output is a long list showing information about each table.
Table = Album
Columns = Title, ArtistId, AlbumId
Primary Keys = AlbumId
Foreign Keys:
ArtistId ---> Artist:ArtistId
Table = Artist
Columns = Name, ArtistId
Primary Keys = ArtistId
Table = Customer
Columns = FirstName, LastName, Company, Address, City, State, Country, PostalCode, Phone, Fax, Email, SupportRepId, CustomerId
Primary Keys = CustomerId
Foreign Keys:
SupportRepId ---> Employee:EmployeeId
Table = Employee
Columns = LastName, FirstName, Title, ReportsTo, BirthDate, HireDate, Address, City, State, Country, PostalCode, Phone, Fax, Email, EmployeeId
Primary Keys = EmployeeId
Foreign Keys:
ReportsTo ---> Employee:EmployeeId
Table = Genre
Columns = Name, GenreId
Primary Keys = GenreId
Table = Invoice
Columns = CustomerId, InvoiceDate, BillingAddress, BillingCity, BillingState, BillingCountry, BillingPostalCode, Total, InvoiceId
Primary Keys = InvoiceId
Foreign Keys:
CustomerId ---> Customer:CustomerId
Table = InvoiceLine
Columns = InvoiceId, TrackId, UnitPrice, Quantity, InvoiceLineId
Primary Keys = InvoiceLineId
Foreign Keys:
TrackId ---> Track:TrackId
InvoiceId ---> Invoice:InvoiceId
Table = MediaType
Columns = Name, MediaTypeId
Primary Keys = MediaTypeId
Table = Playlist
Columns = Name, PlaylistId
Primary Keys = PlaylistId
Table = PlaylistTrack
Columns = PlaylistId, TrackId
Primary Keys = PlaylistId, TrackId
Foreign Keys:
TrackId ---> Track:TrackId
PlaylistId ---> Playlist:PlaylistId
Table = Track
Columns = Name, AlbumId, MediaTypeId, GenreId, Composer, Milliseconds, Bytes, UnitPrice, TrackId
Primary Keys = TrackId
Foreign Keys:
MediaTypeId ---> MediaType:MediaTypeId
GenreId ---> Genre:GenreId
AlbumId ---> Album:AlbumId
You can use the information gathered about each table's relationships to draft a database diagram similar to the diagram 1 shown below.
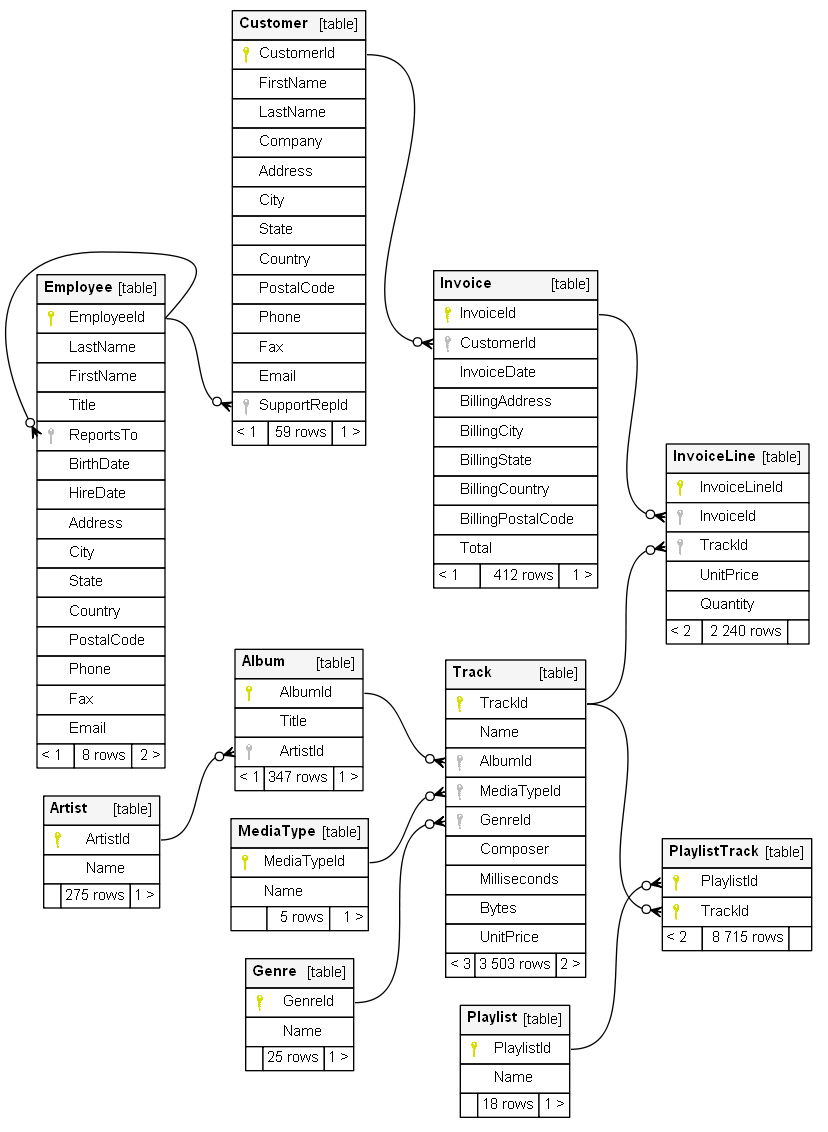
You can also see important details about the database. For example, you can identify that the PlaylistTrack table is an association table that supports a many-to-many relationships between two other tables. A typical association table has two columns and each of its columns are both Primary Keys and Foreign Keys.
Clean up
To clean up, stop the Docker container and deactivate the Python virtual environment:
(.venv) $ docker stop chinook1
(.venv) $ deactivate
$
Conclusion
You used the SQLAlchemy inspection module to gather enough information about the Chinook database schema that you can now write queries that select specific columns and join tables.
You also wrote a program that gathers schema information. If you are working with multiple schemas, you will need to modify the inspect_relationships() function you created.
-
Diagram generated by SchemaSpy and available at https://schemaspy.org/samples/chinook/ ↩